The Wisdom of Data-Driven Decision
Making - DIKW:
Data-driven decision making
Data-driven decision helps organizations to:
- Make
better decisions that are based on facts and evidence, rather than
intuition or gut feeling.
- Identify
and solve problems more effectively.
- Improve
operational efficiency and productivity.
- Develop
new products and services that meet the needs of their customers.
- Gain
a competitive advantage in the marketplace.
The Process
The data-driven decision making process typically involves the following
steps:
- Identify
the problem or opportunity. What are you trying to achieve or improve?
- Collect
relevant data. This could include data from internal sources (e.g., sales
data, customer feedback, operational data) or external sources (e.g.,
market research data, social media data).
- Clean
and prepare the data. This involves removing errors and inconsistencies,
and organizing the data in a way that can be easily analyzed.
- Analyze
the data. This involves using statistical methods and data visualization
tools to identify patterns and trends in the data.
- Interpret
the results. What do the results of the data analysis tell you about the
problem or opportunity you are trying to address?
- Develop
and implement solutions. Based on your interpretation of the results,
develop and implement solutions to the problem or opportunity.
- Monitor
and evaluate the results. Track the results of your solutions to see if
they are having the desired effect. If not, make adjustments as needed.
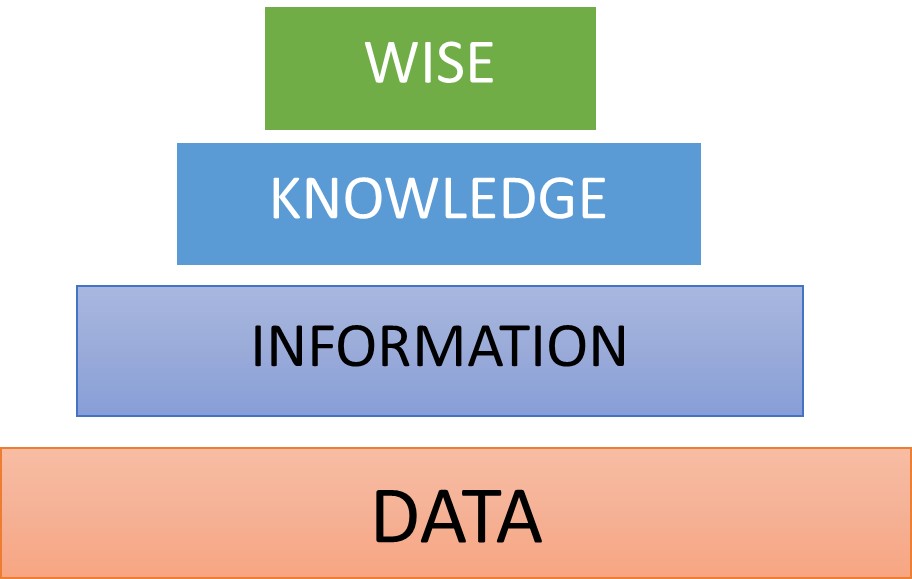
DIKW pyramid
The DIKW pyramid is a conceptual model that describes the relationship
between data, information, knowledge, and wisdom.
- Data: Raw, unprocessed facts. (name, number, address
- Information: Data that has been processed and organized into a
meaningful form. (this is their name, this is their number, this is their
address)
- Knowledge: Information that has been interpreted and understood.
(data model, schema)
- Wisdom:
The ability to apply knowledge to solve problems and make good decisions.
(AI, machine learning)
Data-driven decision making involves climbing the DIKW pyramid, from data
to information to knowledge to wisdom. At each level, the data is transformed
into a more valuable form.
Examples of data-driven decision making
Here are a few examples of how organizations use data-driven decision
making:
- Amazon: Amazon uses data-driven decision making to recommend
products to customers, optimize its supply chain, and develop new products
and services.
- Netflix: Netflix uses data-driven decision making to recommend
movies and TV shows to its users, produce new content, and decide how to
allocate its resources.
- Coles: Coles uses data-driven decision making to optimize
its pricing, inventory management, and store layout, mailing customers
with deals.
- Target: Target uses data-driven decision making to
personalize its marketing campaigns and target customers with relevant
offers.
Leveraging Microsoft Technologies
Microsoft offers a range of technologies and tools that are highly
relevant to Big Data applications. These technologies empower organizations to
manage, process, and derive valuable insights from large and complex data sets.
Here are some key Microsoft technologies in the Big Data landscape:
Microsoft Azure: Azure provides a robust
cloud platform for Big Data solutions. It offers services like Azure Data
Lake Storage and Azure Data Factory for storing and processing large
data sets.
Azure HDInsight: This is a managed cloud
service that makes it easier to set up, operate, and scale Apache Hadoop and
Spark clusters, perfect for Big Data analytics.
Azure Synapse Analytics: Formerly known as SQL
Data Warehouse, this service allows you to query and analyze large volumes of
data using standard SQL.
Azure Databricks: It's a fast, easy, and
collaborative Apache Spark-based analytics platform that's fully integrated
with Azure. It's excellent for processing and analyzing Big Data.
Power BI: Microsoft's business intelligence
tool can be used to visualize and gain insights from Big Data, making it easier
to communicate findings within the organization.
SQL Server Big Data Clusters: With SQL Server 2019,
Microsoft introduced Big Data Clusters, which allow you to deploy scalable
clusters of SQL Server, Spark, and HDFS containers on Kubernetes. This enables
you to run Big Data and relational workloads together.
Azure Machine Learning: For organizations looking
to apply machine learning and AI to Big Data, this platform offers a
comprehensive suite of tools and services.
Cosmos DB: While not strictly a Big Data
technology, it's a globally distributed, multi-model database service that can
handle large volumes of data and scale as needed.
Microsoft's technologies in the Big Data space provide a comprehensive
ecosystem for collecting, storing, processing, analyzing, and visualizing data.
Leveraging AWS
Amazon Web Services (AWS) offers a comprehensive set of technologies and
services for managing, processing, and analyzing Big Data. These AWS
technologies are widely used by organizations to harness the power of large and
complex datasets. Here are some key AWS Big Data technologies and services:
Amazon EMR (Elastic MapReduce): EMR is a cloud-native big
data platform that uses Apache Hadoop, Spark, and other popular frameworks to
process and analyze large datasets.
Amazon Redshift: Redshift is a fully managed data warehouse service that
allows for high-performance querying and analysis of large-scale data.
Amazon S3 (Simple Storage Service): S3 is an object storage service that can store and retrieve large
volumes of data, making it a key component for data storage in Big Data
solutions.
AWS Glue: Glue is a fully managed extract, transform, and load (ETL)
service that makes it easy to prepare and load data for analytics.
Amazon Kinesis: Kinesis offers a set of services for
real-time streaming data, allowing organizations to process and analyze data as
it's generated.
Amazon Athena: Athena is an interactive query
service that allows you to analyze data in Amazon S3 using standard SQL without
the need for complex ETL processes.
AWS Data Pipeline: This service helps you
move data between different AWS services and on-premises data sources, making
it easier to orchestrate data workflows.
Amazon QuickSight: QuickSight is a business
intelligence service that allows you to build interactive dashboards for data
visualization and analysis.
AWS Lambda: Lambda enables serverless computing,
which can be used to trigger data processing and analysis tasks in response to
events.
Amazon SageMaker: SageMaker is a fully
managed service for building, training, and deploying machine learning models
at scale.
AWS Glue DataBrew: It's a visual data
preparation tool that makes it easy to clean and normalize data for analysis.
Amazon Timestream: Timestream is a fully
managed, serverless time-series database for IoT and operational applications.
These AWS technologies are part of a comprehensive ecosystem for Big
Data, offering scalable and cost-effective solutions for organizations of all
sizes. Understanding and using these technologies can help organizations make
informed decisions and gain valuable insights from their data.
Other Tools for Data
In addition to cloud-based services like AWS and Azure, there are several
other tools and frameworks commonly used in the Big Data landscape. These
open-source and commercial tools can help organizations manage, process, and
analyze large and complex datasets. Here are some notable tools for Big Data:
Hadoop: An open-source framework for
distributed storage and processing of large datasets. It includes the Hadoop
Distributed File System (HDFS) and MapReduce for batch processing.
Apache Spark: A powerful open-source framework for
real-time data processing, machine learning, and graph processing. It's known
for its speed and versatility.
Apache Kafka: A distributed streaming platform used
for building real-time data pipelines and streaming applications.
Apache Flink: A stream processing framework for
real-time data analytics and processing.
Cassandra: A highly scalable NoSQL database that
is suitable for handling large volumes of data and real-time data ingestion.
Elasticsearch: A distributed, RESTful search and
analytics engine that is commonly used for log and event data analysis.
Splunk: A commercial platform for searching,
monitoring, and analyzing machine-generated data like logs and events.
Tableau: A popular data visualization and
business intelligence tool that helps users create interactive and shareable
dashboards.
QlikView/Qlik Sense: Business intelligence and
data visualization tools that allow users to explore and visualize data.
Teradata: A data warehousing solution known for
its scalability and powerful analytics capabilities.
Cloudera: A platform that provides a suite of
tools and services for data management and analytics, including Hadoop and
Spark.
Databricks: A unified analytics platform for big
data and machine learning, built on Apache Spark.
Snowflake: A cloud-based data warehousing
platform that enables organizations to store and analyze data at scale.
Neo4j: A graph database that is used for
storing and querying data with complex relationships, ideal for social networks
and recommendation engines.
RapidMiner: An open-source and commercial data
science platform that includes data preparation, machine learning, and
predictive analytics capabilities.
These tools offer a wide range of capabilities and can be tailored to
specific use cases and business needs. When selecting tools for a Big Data
project, it's essential to consider factors such as data volume, data variety,
real-time processing requirements, and the skill set of your team.
Conclusion
Data-driven decision making is an essential part of any successful organization today. By using data to make informed decisions, organizations can improve their performance, gain a competitive advantage, and better meet the needs of their customers.






0 Comments